Code
library(MASS)
library(ggplot2)
library(tidyverse)
library(colorspace)This page produces a coloured version of Figure 5.7 which may be a little easier to read. It also uses standard deviation ellipses to make things a bit clearer (I hope).
library(MASS)
library(ggplot2)
library(tidyverse)
library(colorspace)Next two functions that aggregate either similar or different observations. This is a fairly crude approach but it works. agg_similar() uses integer division to create a ‘grouper’ variable that goes eight 0s, then eight 1s, then eight 2s, and so on up to eight 127s. When group_by is applied using this variable, sets of 8 similar observations are aggregated and the mean taken to give a new dataset.
Conversely, if the grouper variable is based on the remainder from division by 128, we get 8 sequences of 0, 1, 2, 3,… 127, and when these are aggregated into groups, each will consist of eight observations at widely separated positions in the sequence (i.e., with very different values).
# aggregate similar observations
agg_similar <- function(df) {
df |>
mutate(grouper = id %/% 8) |>
group_by(grouper) |>
summarise(x = mean(x),
y = mean(y)) |>
dplyr::select(-grouper) |>
ungroup()
}
# aggregate different observations
agg_different <- function(df) {
df |>
mutate(grouper = id %% 128) |>
group_by(grouper) |>
summarise(x = mean(x),
y = mean(y)) |>
dplyr::select(-grouper) |>
ungroup()
}We also make some plotting functions so we don’t have to repeat a lot of code. These add three plots based on a dataset. A scatterplot of the points, a standard deviation ellipse, and a best fit line. This will make sense when you see the plots.
add_ellipses <- function(g, dfs, cols, alphas, filled_polygons) {
for (i in seq_along(dfs)) {
if (filled_polygons[i]) {
g <- g + stat_ellipse(
data = dfs[[i]], aes(x = x, y = y), geom = "polygon",
alpha = alphas[i], fill = cols[i])
} else {
g <- g + stat_ellipse(
data = dfs[[i]], aes(x = x, y = y), colour = cols[i],
linewidth = 0.35)
}
}
g
}
add_points <- function(g, dfs, cols, alphas) {
for (i in seq_along(dfs)) {
g <- g + geom_point(data = dfs[[i]], aes(x = x, y = y),
colour = cols[i], alpha = alphas[i], pch = 16, size = 1)
}
g
}
add_lines <- function(g, dfs, cols) {
for (i in seq_along(dfs)) {
g <- g + geom_smooth(data = dfs[[i]], aes(x = x, y = y), method = lm,
se = FALSE, colour = darken(cols[i]), linewidth = 0.75)
}
g
}
three_plots <- function(dfs, cols = c("black", "forestgreen", "magenta")) {
g <- ggplot()
g <- add_ellipses(g, dfs, cols, alpha = rep(0.25, 3), filled_polygons = c(F, T, T))
g <- add_points(g, dfs, cols, alphas = c(0.2, 0.5, 0.5))
g <- add_lines(g, dfs, cols)
g +
coord_equal() +
theme_void()
}So now make some datsets and see what we get.
First a dataset with approximate correlation between x and y of 0.5. We then aggregate it two ways and plot the results.
df <- get_correlated_df(0.5)
df_sim <- df |>
agg_similar()
df_diff <- df |>
agg_different()
three_plots(list(df, df_sim, df_diff))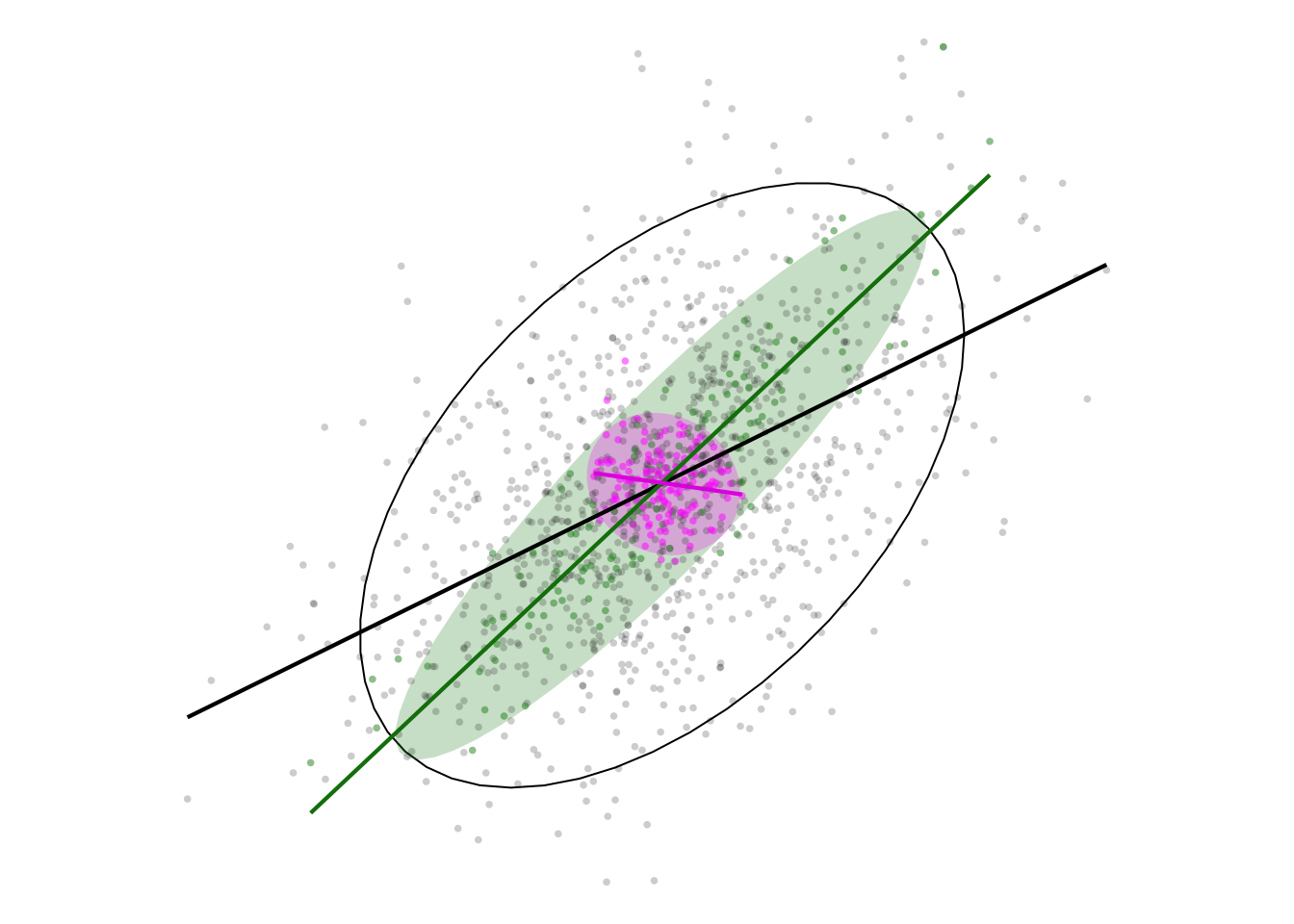
When we aggregate similar observations (the green ellipse) the correlation is increased, while aggregating different observations inverts the correlation (the violet ellipse)! The initial correlation is seen in the unfilled black ellipse.
The effect is even more remarkable for uncorrelated data:
df <- get_correlated_df(0)
df_sim <- df |>
agg_similar()
df_diff <- df |>
agg_different()
three_plots(list(df, df_sim, df_diff))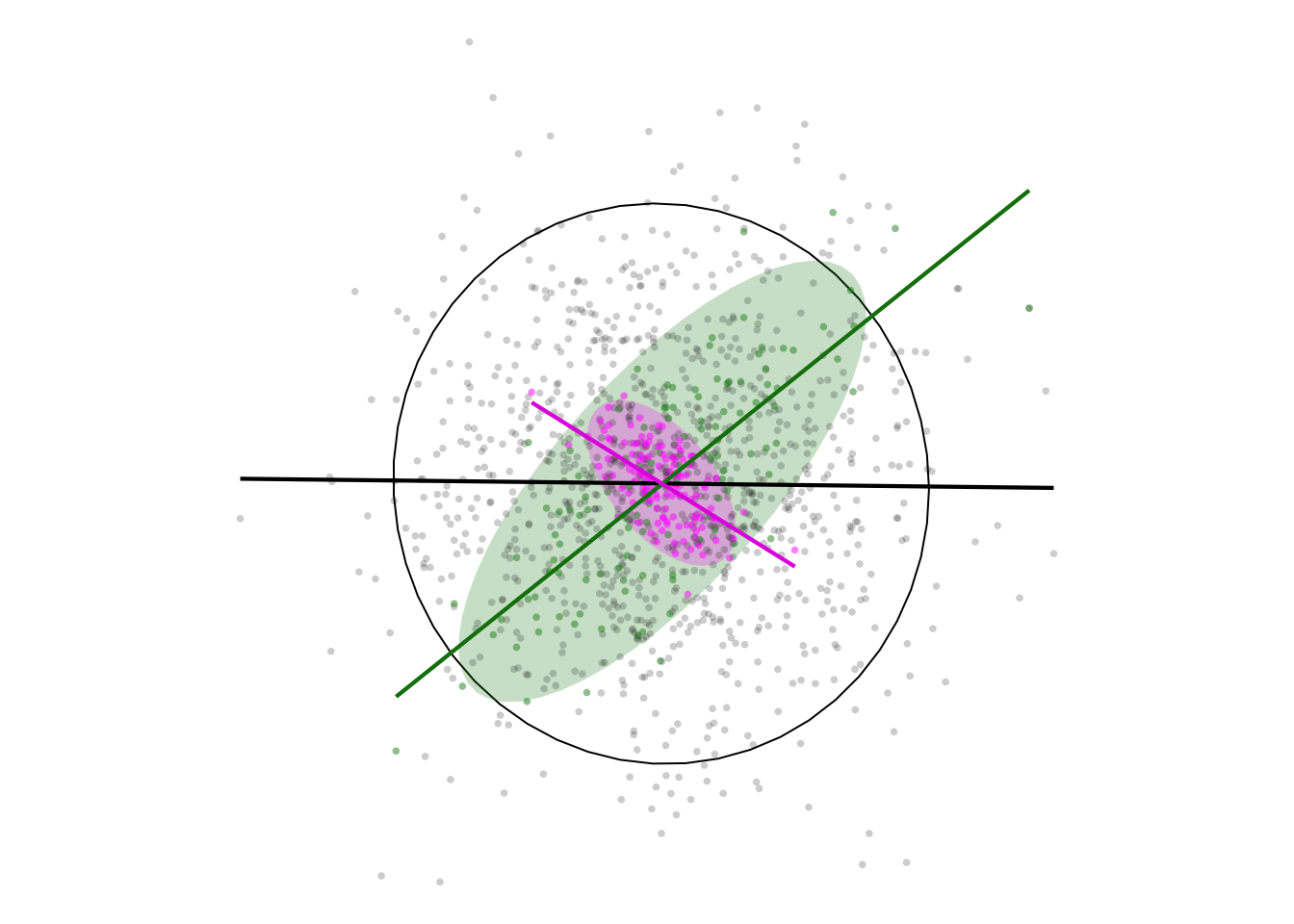
What do we take from this in a geographical setting? Well, if indeed “near things are more related than distant things”, then in many situations where data are aggregated spatially based on proximity positive correlations are likely to be ‘enhanced’, and we may even see correlations where none exist at the individual level.
# License (MIT)
#
# Copyright (c) 2023 David O'Sullivan
#
# Permission is hereby granted, free of charge, to any person
# obtaining a copy of this software and associated documentation
# files (the "Software"), to deal in the Software without restriction,
# including without limitation the rights to use, copy, modify, merge,
# publish, distribute, sublicense, and/or sell copies of the Software,
# and to permit persons to whom the Software is furnished to do so,
# subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included
# in all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
# OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.© 2023-24 David O’Sullivan